题目
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoor" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
可能会想到的办法
开始,可能会想,将words中的所有单词去进行全排列,然后再用排列好的字符串作为待匹配串去s中找,子串匹配的话,KMP算法就好了,时间复杂度是O(n)级别的,当然KMP算法里面求next数组是O(m)级别的(假设待匹配串的长度为m),KMP算法可以看我之前写的一篇文章>KMP子串匹配<,所以如果这里用KMP算法的话,时间主要会花在将words中的所有单词去进行全排列上,是O(num!)级别的(这里假设words数组一共包含num个单词)。这种方法我没试过,不知道行不行,题目也好像没怎说words长度的数量级。
因为这道题是被分类在LeetCode的双指针category里的,所以,还是想想双指针怎么用在这个场景中,这里参考了>这篇博客<中的思路,我这里用C++实现的,大致讲下思想:
因为题目中说了,words里面的各个单词之间如何组合是不重要的,可以打乱顺序,但是我们带球的是s串的一个子串,这个子串中间是不能被劈开的,必须是连续的。
以下以示例1为例说明:
首先,统计一下words词汇列表里面各单词的出现次数,我们在s串中匹配时是按单词为基本单位的。这里选用字典就好,python实现会很方便,c++的话用STL里面的map数据结构即可。
1
2
| words_dict[“foo”]=1
words_dict[“bar”]=1
|
然后,双指针的任务到了,最开始左右指针指向一个地方。指针移动的过程中是以单词长度为单位的,因为words数组里面的单词长度都是一样的。先移动right,移动的过程中,匹配到了某个单词,就把该单词的出现次数也统计到一个新的字典(或者说map)里面,如果和words中的统计数量一样,那就是一个成功匹配,返回当前left下标,然后再右移left指针,继续往后匹配(别忘了更新left指针扫过的单词出现次数,即减1)。

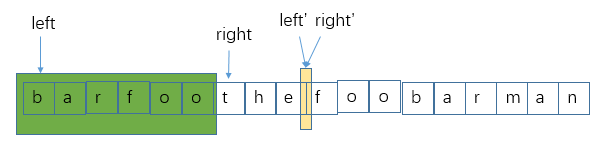
当然,如果在移动right的过程中,扫过的单词根本没在words里面出现过,那right继续右移一个单词长度,并且把left移到和right一样的地方,如下图left’,right’和黄色区域所示(可以看作是把前面的9个字符全切掉,从现在一个新的位置重新开始了):
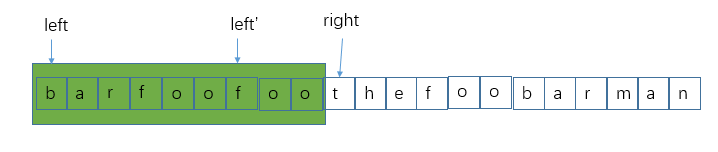
还有就是,如果在right移动的过程中发现,某个单词出现的次数比words还多,那必须得移动left指针,让这个出现次数多了的单词出现次数减少。移到什么时候呢?是的,次数不比words中出现次数多即可,就像下面这种状态:
当然,还有可能出现下面这种情况,这里也肯定是可能出现的,假设words中每个单词的长度为r,所以left和right从0~(r-1)这几个下标分别开始寻找:

主要思路就是这样,看python代码可能会对算法的思路看的更清晰,我也推荐你看>这篇博客<中的代码
下面是我用c++实现的,用到了vector和map两种数据结构,非常简单的运用了一下,写代码时注意一下边界情况,如果words或s为空,那么返回空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| #include<iostream>
#include<vector>
#include<map>
using namespace std;
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> result;
if(words.size()==0 || s.length()==0)
return result;
map<string,int> words_map;
int word_len=words[0].length();
int word_num=words.size();
if(word_len>s.length())
return result;
for (vector<string>::iterator it = words.begin();it != words.end();it++)
{
if(words_map.count(*it))
words_map[*it]++;
else
words_map[*it]=1;
}
for (int i = 0;i < word_len;i++)
{
int left = i, right = i;
int cur_num = 0;
map<string, int> s_map;
string right_str, left_string;
while (right <= s.length() - word_len)
{
right_str = s.substr(right, word_len);
if (!words_map.count(right_str))
{
right += word_len;
left=right;
cur_num=0;
s_map.clear();
}
else
{
if (!s_map.count(right_str))
s_map.insert(pair<string, int>(right_str, 1));
else
s_map[right_str] += 1;
cur_num += 1;
right += word_len;
if (s_map[right_str] > words_map[right_str])
{
while (s_map[right_str] > words_map[right_str])
{
string left_str = s.substr(left, word_len);
s_map[left_str]--;
cur_num--;
left += word_len;
}
}
if (cur_num == word_num)
{
result.push_back(left);
s_map[s.substr(left,word_len)]--;
left+=word_len;
cur_num--;
}
}
}
}
return result;
}
};
int main()
{
Solution solution;
string s = "wordgoodgoodgoodbestword";
vector<string> word;
word.push_back("word");
word.push_back("good");
word.push_back("best");
word.push_back("good");
vector<int> rs=solution.findSubstring(s,word);
for (vector<int>::iterator it = rs.begin();it != rs.end();it++)
{
cout<<*it<<" ";
}
return 0;
}
|